Blogger shows the latest post on the top. Therefore the older posts are pushed down. To get the correct sequence, please start reading from the bottom. Thank you.
-kiran
(If you are not able to see images, right click and select "View Image" in Internet Explorer or visit the original link in maayboli देवनागरी ‘लिपी’चा अपभ्रंश (भाग २))
दुसरा भाग लिहीण्यासाठी मी किरण फाॅण्ट वापरला आहे कारण लिपी वरील कोणतेही illustration Unicode च्या आवाक्याबाहेर आहे.
किरण फाॅण्ट http://www.kiranfont.com येथून मोफत मिळवा.
भाग दुसरा : सगळ्यात अपभ्रंशित झालेले देवनागरी अक्षर ‘र’
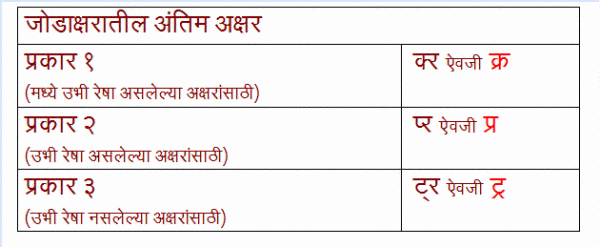
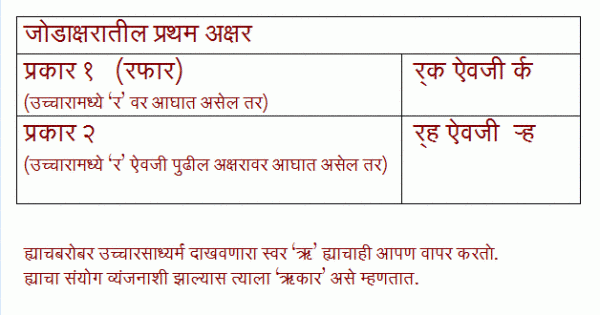





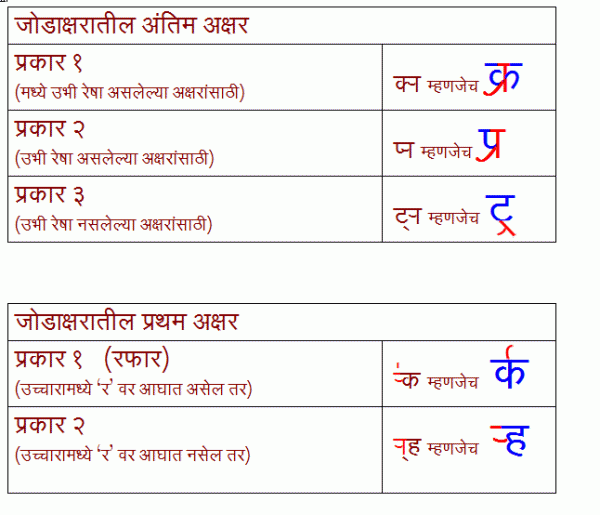
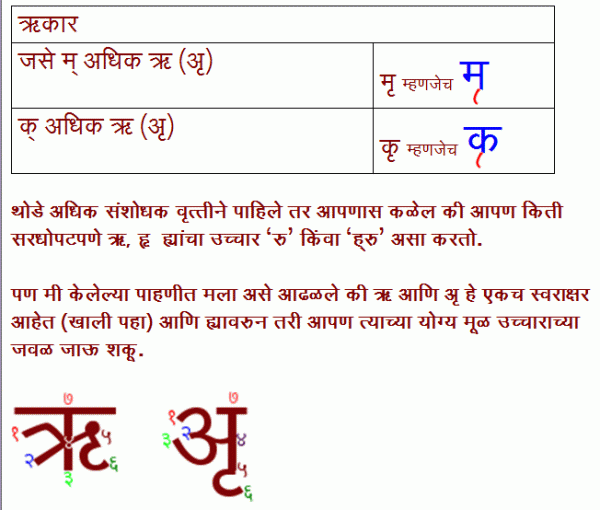
(हा माझा लेख मायबोली.कॉम वर पूर्वप्रकाशित अाहे त्याचे दुवे)
देवनागरी ‘लिपी’चा अपभ्रंश (भाग १)
देवनागरी ‘लिपी’चा अपभ्रंश (भाग २)
नमस्कार! सर्वसाधारणपणे अापण नेहमी अमुक शब्दाचा ‘अपभ्रंश’ तमुक अाहे असे म्हणतो. जसे की अॉफिस चा अपभ्रंश होअुन हापिस हा शब्द. हॉस्पिटल चे अीस्पितळ, िअ. वरील अुदाहरणे िअंग्रजी शब्दांची अाहेत. मात्र मराठी शब्दांतही असे बदल घडुन येतात. जसेः जाहला – झाला. पण हे सर्व अपभ्रंश अुच्चाराबाबत अाहेत. अपभ्रंशाची सोपी व्याख्या म्हणजे ‘भ्रष्ट नक्कल’. भ्रष्ट म्हणजे जी मूळ प्रतिशी समरुप नाही अशी.
अापण कधी हा विचार केला अाहे का की असा प्रकार अापल्या लिहीण्याच्या पद्धतीत देखील होतो / होअु शकतो? वर्षानुवर्षे देवनागरी लिपी अनेक लोक वापरत अालेले अाहेत. त्यातील अनेक वैशिष्ट्यांमुळे संस्कृत शिवाय अनेक भाषेतील मजकूर जतन करण्यासाठी देवनागरी लिपी वापरली गेली / जात अाहे. मराठी व हिंदी ही नेहमीची अुदाहरणे. मात्र खुप कमी लोकांना हे माहित असेल की देवनागरी लिपी १४ पेक्षा अधिक भाषांसाठी वापरली जाते.
अापल्या पुर्वजांनी देवनागरी लिपी तयार करताना अनेक बाबींचा शास्त्रोक्त विचार केला होता, मात्र वर सांगितल्याप्रमाणे त्यात वेळोवेळी बदल घडत गेले अाणि तत्कालिन कालानुरुप हे बदल ग्राह्य मानले गेले. मात्र अनेक भाषा देवनागरीचा वापर करत अाल्याने त्या त्या भाषेसाठी अनुकूल असेही काही बदल करण्यात अाले अाणि ते काही भाषांपुरते मर्यादित राहिले.
अुदाः हिंदी भाषिकांनी खासकरुन अुर्दू अुच्चारातील बदल कळावा म्हणून नुक्ता (अधोबिंदू ़ कागज़) वापरणे सुरु केले. तसेच काही हिंदी अक्षरे (अ, झ, अंक ५, ८) हे हिंदीत वेगळ्या पद्धतीने लिहीतात.
मराठीत श अाणि ल यांचे लेखन वेगळ्या प्रकारे केले जाते.
केवळ मराठीमध्ये असलेले ‘ळ’ हे विशेष अक्षर हिंदी व संस्कृत मध्ये देखील नाही.
सिंधी भाषादेखील काही ठिकाणी देवनागरीत लिहिली जाते. तिथे काही अक्षरांना अधोरेषा अाहे. (ॻ)
ह्या सर्व नंतरच्या पुरवण्या अाहेत ज्या अापापल्या सोयीप्रमाणे घातलेल्या अाहेत. अॅ व ऑ ह्या अगदी अलिकडच्या मराठीतील भरी!
ह्या भरींबरोबरच काही अक्षरे (मुख्यतः स्वर) त्यांच्या अुच्चारांसकट लयासही गेली अाहेत. जसे की दीर्घ ऋ = ॠ. ऌ व ॡ. ह्यातील ऌ हा मराठीतील क्ऌप्ती ह्या अेकमेव माहित असलेल्या शब्दामुळे जिवंत अाहे.
मात्र मी जो अपभ्रंश म्हणतोय तो हा नव्हे. मूळ देवनागरी लिपीपासून फारकत व्हायला फार पूर्वीपासून सुरुवात झाली असावी. ह्याचे मुख्य कारण एका पिढीपासून दुसऱ्या पिढीकडे केवळ भुर्जपत्रावरील हस्तलिखीताच्या स्वरुपातच हस्तांतर झाले. शिवाय प्रत्येकाच्या लिहीण्याच्या वेगळ्या पद्धतीमुळे त्यात बदल घडत गेले. छपाईचे तंत्रज्ञान अाल्यावर त्या वेळी वापरात असलेल्या लिपीमधे पुढील बदल घडणे थोडे स्थिरावले.
हे बदल कसे घडले असावेत ते अापण पुढच्या भागात पाहू. मात्र पुढचा भाग लिहीण्यासाठी मला किरण फाॅण्ट ची गरज पडेल कारण लिपी वरील कोणतेही illustration Unicode च्या अावाक्याबाहेर अाहे.
किरण फाॅण्ट http://www.kiranfont.com येथून मोफत मिळवा.
(भाग १ समाप्त)
देवनागरी ‘लिपी’चा अपभ्रंश (भाग २)
काही महत्वाच्या प्रतिक्रिया
limbutimbu | 2 August, 2010 - 23:23
>>>> केवळ मराठीमध्ये असलेले ‘ळ’ हे विशेष अक्षर हिंदी व संस्कृत मध्ये देखील नाही.
माझ्याकडील पुस्तकात, श्री विष्णूसूक्तात दुसरा श्लोक असा आहे
इदं विष्णुर्विचक्रमे त्रेधानिदधे पदम
समूहळमस्य पांसुरे
हा ळ नन्तर ल ऐवजी प्रक्षिप्त असेल का? जाणकारान्नी खुलासा केल्यास बरे होईल स्मित
किरण | 3 August, 2010 - 14:28
लिंबू: संस्कृत मध्ये ळ नाही हे नक्की. बरेच संस्कृत शब्द मराठीत आहेत पण काही शब्द ज्यात मराठी रुपात ळ आहे तो संस्कृत मध्ये ल आहे उदा: कमळ = कमल नळ = नल इ.
बहुधा ती प्रिंटींग मिस्टेक असावी.
अथर्वशीर्षातही "ॐ गं गणपतये नमः" आणि "स ग हिता संधी" ह्या २ ठिकाणी ग च्या जागी वेगवेगळ्या पुस्तकात वेगवेगळी चिह्ने वापरलेली मी पाहिली आहेत. काही ठिकाणी आणि आता बर्याच पुस्तकात तर "संहिता संधी" असेही वाचले आहे. अशी बरीच चिह्ने आपण हरवलेली आहेत
उच्चाराबबतही योग्य निरीक्षण. मला तर असे वाटते की आपल्या भाषेचे ते वैशिष्ट पूर्वी तरी नक्किच असे होते की तो शब्द ऐकल्यावर त्याच्या उच्चारावरुनच त्याचा अर्थ अभिप्रेत व्हावा.
जसे सॅड गाणे ऐकल्यावर शब्दांशिवायच ते दु:खी गाणे आहे हे समजावे त्याप्रमाणे.
Why Unicode Devanagari cannot take the Crown of a Standard.
Have you ever seen the Unicode Code Chart for Devanagari? If not, please take look at
http://www.unicode.org/charts/PDF/U0900.pdf
Now can anybody answer following questions and provide some logical answers?
1. Why does the chart have Vowel Signs (like ु) and Vowel Symbols (like अु = उ) BOTH? The Vowel Symbols can be accurately expressed as the combination of अ and respective Vowel Sign?
2. If it was the intention why there is no separate place for these vowels and has only signs: अं, अः They are left to be expressed as a combination of 2 characters. i.e. Vowel अ and the respective vowel signs for anuswar and visarg?
3. If we assume that the criteria was that the Glyph (Visual appearance) is different as in case of इ or उ then why was a separate character (CODE POINT) required for आ ?
4. Interesting to note is following are valid Vowel - Symbol combinations with अ!
Now again strangely, following are shown correctly in this blog / Internet explorer but not in MS Word except the last 2
अि अी अु अू अे अै अं अः
Which means it is left to the interpretation of the OS, rendering engine, receiving application and the font itself.5. Following combinations are not even shown correctly in the internet explorer application
अा अो अौ
6. If we think rationally that the chart has placed both Vowel Signs (like ु) and Vowel Symbols (like अु = उ), then again we are wrong! अं & अः being valid Vowels do not have a space in the Unicode chart!!
7. While the chart has no place for half consonant characters that have distictive identity both Grapical and Pronunciative, it finds place for some Silly virtually non-existant characters such as ऄ ऒ ऎ ॆ ॊ
8. Where Unicode plays with the basic building blocks of the script - Vowels in this fashion, why characters with Nukta not coded with the character followed by the nukta character 093c (़). For example, (U+0915 U+093c) क ़ = क़ but has another code U+0958 (क़). Same is done for 10 more such characters
9. On similar lines, for Sindhi Implosives, why it cannot use (U+0917 U+0952) ग ॒ = ग॒ but has another code U+097b (ॻ). same is done for 3 more such character codes
10. In marathi letters ksha क्ष and dnya ज्ञ are assumed to be whole consonants. They make a place in very basic kindergarden books "anklipi" and appears in the basic lists of consonants in Marathi. However, Unicode treats them as a "jodakshar" combination characters as क,ष for क्ष and ज, ञ for ज्ञ. Although pronunciation-wise the combination appear equivalant, the Hindi pronuntiation of the later combination character does not represent ज्ञ. For Hindi pronuntiation equivalance the combination should have been ग and य as in ज्ञान. But the basic thing is that, क्ष and ज्ञ should have got there own code place in the chart that it has not.